Search for answers or browse our knowledge base.
SYNCNOW
![]() SyncNow – connect teams , tools and processes
SyncNow – connect teams , tools and processes
High Availability
Overview
SyncNow enterprise edition supports establishing a cluster of SyncNow cluster.SyncNow cluster is a group of nodes in an active-active form. SyncNow requests are queued, every node can get a sync or devops request and process it. SyncNow cluster enables the continuation of Synchronizations and DevOps gate processes even if one or more nodes fails.
Architecture
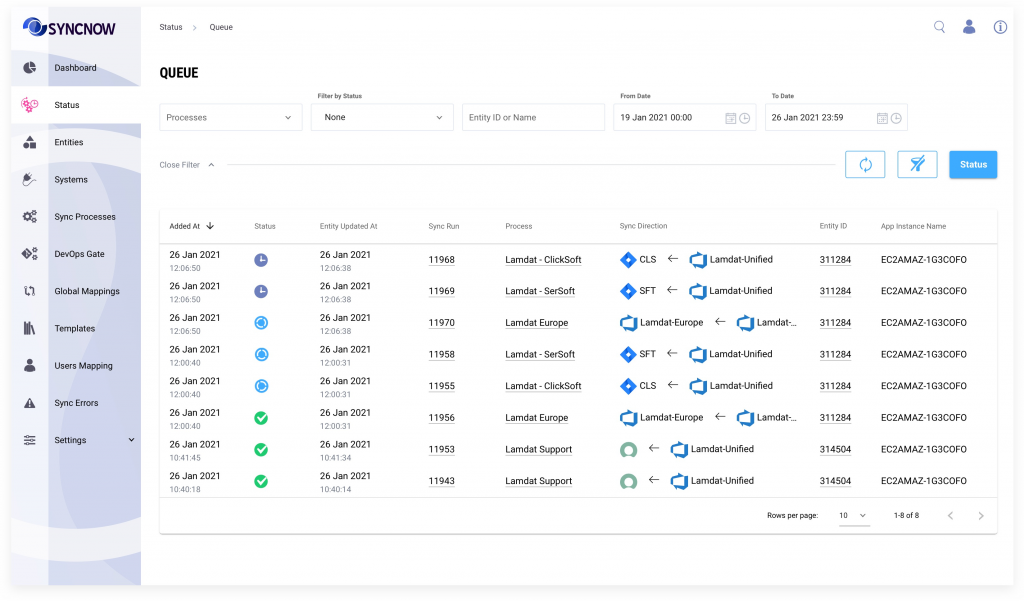
SyncNow cluster consists of at least two nodes. Every cluster has a main server which is elected if one of the nodes fails. The main server executes unique processes for example – purging jobs, sync template processing. SyncNow stores all the work in queue , every node can fetch requests from the queue and process them, the queue can be view from SyncNow User Interface.
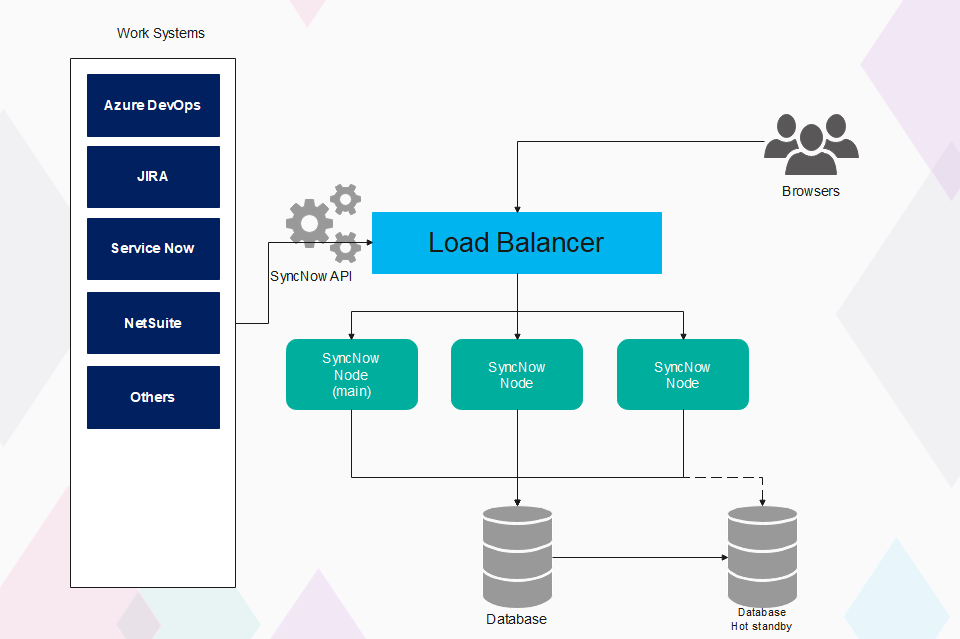
These are the requirements to set up SyncNow cluster :
Load Balancer
A load balancer that can transfer http requests to every node
App Nodes and Number of Nodes
SyncNow Enterprise app instance, it can be in the form of a docker or app deployed on Linux | Windows systems. All nodes should be connected to the same database. SyncNow does not store any important information inside app nodes.
The minimal number for High Availability is two SyncNow nodes.
Database
Database in a cluster active-passive configuration. We support SQL Server Clusters and PostrgreSQL cluster.
Cloud Native
We do not regularly test all cloud native scenarios. SyncNow was tested with AWS EKS and Azure AKS in the past. Contact us if you want to ask about more deployment options.
Failures and recovery
SyncNow cluster can automatically recover from failures.
- Nodes identify if there is main node has failed ,a new one will be elected
- If one of the nodes fails another will node will take over its operations
- The cluster can grow and automatically split tasks to multiple nodes
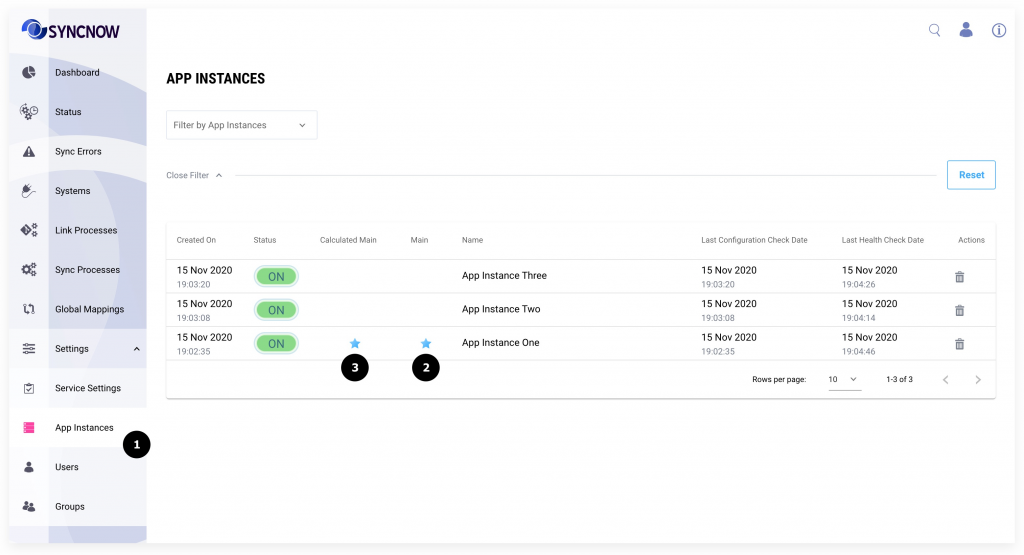
Cluster view and Operations
- Go to the App Instances page
- Star 2 shows the current main app instance. Main instance executes purge cycling jobs
- Star 3 shows the calculated main instance. If a calculated main instance is not operational then will be elected new main instance. But as soon the calculated main instance will become again operational, it will rain become main